- 发布于
Avolve Part-1
- 作者

- Name
- CuB3y0nd
- GitHub
- @CuB3y0nd
对于本项目,将使用神经网络和遗传算法进行模拟进化。本项目基于原始项目 Shorelark。
下面我将向你介绍一下基本的神经网络和遗传算法的工作原理,然后我们将在 Rust 中实现这两种算法,并将我们的应用程序编译为 WebAssembly,最终得到:

我会分四篇文章记录整个项目的实现,大致如下:
设计
首先明确我们的目标:我们实际上要模拟什么?
总体思路是,我们有一个代表世界的二维平面:

这个世界由鸟类组成:

……和食物(一种抽象的,富含蛋白质和纤维):
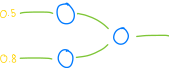
每只鸟都有自己的视觉,使它们能够找到食物:
……以及控制鸟的身体(速度和旋转)的大脑。
这个项目的神奇之处在于,我们将采取一条更有趣的路线,而不是将鸟硬编码为某些特定行为(例如「去吃掉你视野中最近的食物」):
大脑
仔细看,你会发现大脑只不过是一个某些输入到某些输出的函数,例如:

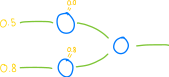
由于我们要实现的鸟只有视觉输入,因此它们的大脑可以近似为:
在数学上,我们可以将该函数的输入(鸟的眼睛)表示为一个数组,每个数字(鸟的感光器)描述离最近的物体(食物)的距离:

Tip
为了简单起见,我们的鸟看不到颜色 - 您可以使用光线追踪使眼睛更加真实。
至于输出,我们可以使函数返回一个有关速度变化和旋转变化 的元组。
例如,大脑告诉鸟 意味着「速度增加 个单位并顺时针旋转 度」,而 意味着「保持速度和方向不变,稳定前行」。
重要的是,我们使用的是相对值(速度变化量和旋转变化量)。因为鸟的大脑不会意识到自己相对于世界的位置和旋转——传递该信息只会增加大脑的复杂性,吃力不讨好。
最后,让我们谈谈房间里的大象:所以大脑基本上就是 ,对吗?但是我们如何找出等号后面到底是什么呢?
神经网络 (Neural Network) 简介
作为人类同胞的一员的你,你可能知道大脑是通过突触连接的神经元组成的:
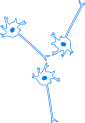
突触在神经元之间传递电信号和化学信号,而神经元决定给定的信号是否应该进一步传播或停止;最终,这使得人们能够识别文字、吃饭睡觉,并在网络上发表刻薄的评论。
由于其固有的复杂性,生物神经网络并不是最容易模拟的。因此,聪明的人类发明了一类被称为 人工神经网络 (Artificial Neural Networks) 的数学结构,它允许使用数学方法近似模拟类似大脑的行为。
人工神经网络(下文统一简称为神经网络)在数据集泛化方面表现突出(例如识别猫的样子),因此它在人脸识别(例如用于相机)、翻译(例如用于 GNMT)方面有着广泛的应用。在我们的例子中,可以控制一些彩色像素以换取少量的 reddit 积分。
对于我们的项目,主要关注 前馈神经网络 (Feedforward neural network, FFNN)……
……它看起来像这样:
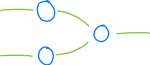
这是 FFNN 的布局,它具有 五个突触 和 三个神经元,全部组织为两层:输入层 (Input Layer)(左侧)和 输出层 (Output Layer)(右侧)。
中间还可能存在别的层,它们被称为 隐藏层 (Hidden Layers)——它们提高了网络理解输入数据的能力(想一想:大脑越大,在某种程度上它就可能理解的「越抽象」)。
与生物神经网络(依靠电信号)相反,FFNN 的工作原理是在输入中接受一些 数字,并在整个网络中逐层传播(前馈)这些数字;最后一层出现的数字决定网络的最终结果。
例如,如果向网络提供图片的原始像素,你可能会收到这样的响应:
- - 这张照片不包含正在吃烤冷面的橙色的猫
- - 这张照片可能包含一只正在吃烤冷面的橙色的猫
- - 这张照片一定包含一只正在吃烤冷面的橙色的猫
网络也可以返回许多值(输出值的数量等于输出层中神经元的数量):
- - 这张照片不包含橙色的猫,但可能包含烤冷面
- - 这张图片可能包含一只橙色的猫,但不包含烤冷面
输入和输出数字的含义取决于你,我们只是想象存在一些神经网络以这种方式运行,但实际上,你需要准备所谓的 训练数据集 (Training Dataset),「鉴于这张图片,你应该返回 」,「鉴于这张图片,你应该返回 」。
你可以创建一个网络来识别成熟的苹果,这完全没有问题!
知道 FFNN 的总体概述后,现在让我们采取下一个主要步骤,了解实现这一切的魔力。
神经网络:深入研究
FFNN 依赖于两个构建块:神经元和突触。
神经元(通常用圆圈表示)接受一些输入值,对其进行处理,并返回一些输出值;每个神经元至少有一个输入,最多有一个输出:
此外,每个神经元都有一个 偏置 (Bias):
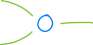
偏置就像神经元的 if 语句——它允许神经元保持不活动状态(输出零),除非输入足够强(高)。从形式上来说,我们会说偏置可以调节神经元的 激活阈值 (Activation Threshold)。
想象一下,你有一个具有三个输入的神经元,每个输入决定它是否看到烤冷面 (1.0) 或没有 (0.0)。现在,如果你想创建一个在看到至少两个烤冷面时激活的神经元,你只需创建一个偏置为 的神经元; 这样,你的神经元的「自然」状态将为 (不激活),一个烤冷面时为 (仍然不激活),两个时为 (激活)。
Tip
如果我的烤冷面比喻对你没有吸引力,那你可能会认为这个基于数学的解释对你更有帮助。
除了神经元之外,我们还有 突触 (Synapses)。突触就像一根导线,将一个神经元的输出连接到另一个神经元的输入;每个突触都有一定的 权重 (Weight):
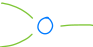
权重是一个因子(因此每个数字之前都有 「x」号,用以强调其乘法性质),因此权重为:
- - 意味着突触实际上已经死亡(它不会将任何信息从一个神经元传递到另一个神经元)
- - 意味着如果神经元
A返回 ,神经元B将收到 - - 意味着突触实际上是直通的。如果神经元
A返回 ,神经元B将收到
记住所有这些知识后,让我们回到我们的网络并用一些随机数填充那些缺失的权重和偏差:
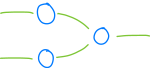
瞧她多么美丽呀,不是吗?哈哈
让我们看看它的想法,比如输入 :
重申一下,我们只对最右边神经元(即我们的输出层)的输出值感兴趣。因为它取决于前面的两个神经元(来自输入层的神经元),所以我们将从它们开始。
让我们首先关注左上角的神经元——为了计算其输出,我们首先计算其所有输入的 加权和:
……然后,我们加上偏置:
……并通过所谓的激活函数限制该值;激活函数将神经元的输出限制在预定义的范围内,模拟类似 if 的行为。
最简单的激活函数是 修正线性单元 (Rectified Linear Unit, ReLU),在 rust 中为 f32::max:
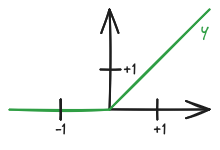
Note
另一个比较流行的激活函数是 tanh,它的图形看起来略有不同(形如 s)并且具有不同的属性。
激活函数影响网络的输入和输出。例如,与 ReLU 相比,tanh 强制网络处理 范围内的数字,而不是 。
正如你所看到的,当我们的带偏置的加权和低于零时,神经元的输出将为 。这正是我们当前输出所发生的情况:
不错。现在我们来做另一个:
加权和:
偏置:
激活函数:
至此,我们已经完成了输入层:
……这将我们引向最后一个神经元:
加权和:
偏置:
激活函数:
……以及网络的输出本身:
对于 的输入,我们的网络输出为 。
(因为这只是在一个完全虚构的网络上的练习,所以这个数字没有任何意义。它只是一些输出值。)
总的来说,这是最简单的 FFNN 之一。给定适当的权重,它能够解决XOR 问题,但可能缺乏引导鸟类的计算能力。
更复杂的 FFNN,例如:

……工作方式完全相同:只需从左到右,逐个神经元计算输出,直到压缩输出层中的所有数字。
此时你可能会好奇:「等等,我如何知道网络的权重?」,对此有一个简单的答案:
如果你习惯了确定性算法(冒泡排序,有人吗?),这对你来说可能感觉不合逻辑,但对于包含多个神经元的网络来说,事情就是这样的:你交叉手指,随机化初始权重,并利用你所拥有的东西进行工作。
请注意,我说的是初始权重。有了一些非零权重,你可以在网络上应用某些算法来改进它(本质上是教它)。
FFNN 最流行的「教学」算法之一是反向传播:
你以「对于这个输入,你应该返回那个输出」的形式向你的网络展示大量的例子(「对于这张抱枕的图片,你应该返回枕头」),并且反向传播慢慢地调整你的网络的权重,直到得到正确的答案。
或者不是。网络可能会陷入局部最优 (Local Optimum) 状态并「只是」停止学习。
另外,如果你发现自己在做神经网络填字游戏,请记住反向传播是监督学习 (Supervised Learning) 的一个例子。
如果你有一组丰富的标记示例(例如照片或统计数据),则反向传播是一个很好的工具,这就是为什么它不符合我们最初的假设:
我们不是统计学家,世界是一个残酷的地方,我们希望我们的鸟能够自己弄清楚所有的学习。
解决方案?
生物学遗传算法和大数法则的魔力!
遗传算法 (Genetic algorithm) 简介
回顾一下,从数学的角度来看,我们所面临的根本问题是我们有一个由大量 参数 定义的函数(使用神经网络表示):
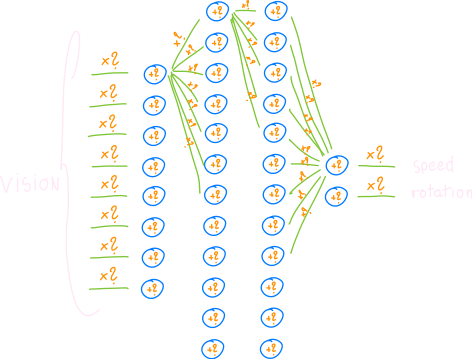
(我没有费心画出所有的权重,但我希望你明白这一点——权重有很多。)
如果我们用单精度浮点数表示每个参数,那么仅由 3 个神经元和 5 个突触组成的网络就可以定义为多种不同的组合……
……宇宙很快就会迎来它的最终命运,而不会等我们检查完所有这些数。我们当然得变得更聪明!
所有可能的参数集称为 搜索空间 (Search Space)。
由于迭代搜索空间寻找单个最佳答案是不可能的,因此我们可以专注于查找次优答案列表这一更简单的任务。
遗传算法:深入研究
这是一株野生胡萝卜,以及它的栽培品种:

这种栽培的、广为人知的形式并不是凭空出现的——它是数百年选择性育种的结果,考虑到了某些因素,比如主根的质地或颜色。
如果我们能用我们的神经网络做类似的事情,那不是很棒吗?如果我们只是随机创造了一群鸟,并选择性地培育出那些看起来最突出的鸟……
事实证明,我们并不是第一个偶然发现这个想法的人。计算机科学中已经存在一个被广泛研究的分支,称为进化计算 (Evolutionary computation),它的目的就是「按照自然的方式」解决问题。
在所有进化算法中,我们将研究的具体子类称为遗传算法。
Important
与神经网络类似,遗传算法也不是一个具体的算法,而是一系列不同的算法;因此,为了避免熬夜,我们将简单介绍一下它的工作原理。
从上到下开始,遗传算法从 种群 (Population) 开始:

群体由 个体 (individuals)(有时也被称为 代理 (Agents))组成:

个体(或代理)是给定问题的单一可能解决方案(因此,种群是一些可能解决方案的集合)。
在我们的例子中,每只鸟都会模拟一个大脑(或者整个鸟,如果你喜欢以这种方式可视化),但通常这取决于你要解决的问题:
一个个体代表了某种解决方案,但不一定是最好的,甚至不一定是最理想的解决方案。
个体是由 基因 (Genes)(统称为 基因组 (Genome))构成的:

基因是由遗传算法评估和调整的单个参数。
在我们的例子中,每个基因只是一个神经网络的权重,但表示问题的领域并不总是那么简单。
例如,如果你正在解决旅行商问题,其中的基本问题与神经网络无关,那么一个基因可以是一个由 坐标组成的元组,确定旅行商旅程的一部分(因此,一个个体将描述旅行商的整个路径):

现在,假设我们有五十只鸟的随机种群。我们将它们传递给遗传算法,会发生什么?
与选择性育种类似,遗传算法首先评估每个个体(每个可能的解决方案),看看哪些是当前种群中最好的。
从生物学上来说,这相当于到你的花园散步并检查哪些胡萝卜是最橙色和最美味的。
可以使用所谓的 适应度函数 (Fitness Function) 进行评估,该函数返回一个 适应度分数 (Fitness Score),量化特定个体(即特定解决方案)的好坏程度:
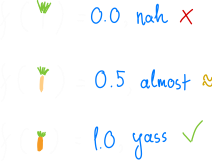
对于遗传算法而言,创建可用的适应度函数是最困难的任务之一,因为通常有许多指标可以用来衡量个体。
(即使是我们容易想象的胡萝卜也至少有三个指标:主根的颜色、半径和味道,必须将它们压缩成一个数字。)
幸运的是,对于本项目的鸟类来说,我们没有太多选择:我们只能说,一只鸟的好坏取决于它在这 一代 (Generation) 人中所吃的食物量。
一只吃了 种食物的鸟比只吃了 种食物的鸟要好,就这么简单。
Tip
否定适应度函数 (Negating a fitness function) 会使遗传算法返回最差的解决方案而不是最好的解决方案;只是一个有趣的技巧,供以后记住。
现在,遗传算法的巅峰时刻已经到来:繁殖 (Reproduction)!
从广义上讲,繁殖是从当前种群开始建立新种群(希望略有改善)的过程。
这在数学上相当于选择最美味的胡萝卜并播种。
发生的情况是,遗传算法随机选择两个个体(优先考虑适应度得分较高的个体)并使用它们来产生两个新个体(所谓的 后代 (Offspring)):
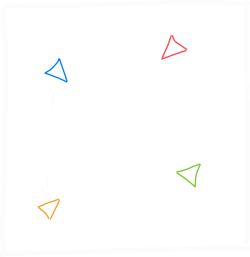
后代是通过获取父母双方的基因组并对其进行 交叉 (Crossover) 和 突变 (Mutation) 而产生的:
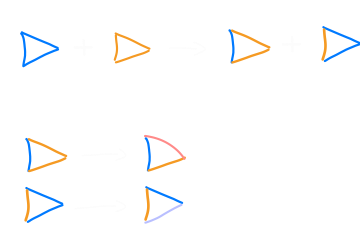
交叉允许混合两个不同的个体以获得近似的中间解决方案,而突变允许发现初始群体中不存在的新的解决方案。
两个新产生的个体都被推入新种群池中,并且该过程重新开始,直到整个新种群建立;然后当前的种群被丢弃,整个模拟从这个新的(希望得到改进)种群开始。
正如你所看到的,这个过程中有很多随机性:我们从随机群体开始,我们随机化基因的分布方式……所以……
代码
让我们用一个悬念来结束这篇文章:
mkdir Avolve
在 Part-2 中,我们将实现一个有效的、基本的前馈神经网络!
参考
以下是我个人认为在了解本文中介绍的主题时有用的一些参考: